
#1 Linux filesystem benchmark 2008/1
Filesystem benchmarks are an aging topic. As long as there existed multiple Linux filesystems, endless filesystem benchmarks (and flamewars) where created.
However, when I was about to setup a little larger box the other day - not only all the automated T2 software landscape compilation, but also our other in-house builds, regression testing and other scientific stuff - a question came up: "What filesystem to choose on a 8-way Xeon with 4 SATA discs forming a RAID5 array?".
Historically ReiserFS (v3) always pleased us very well and we where running it exclusively on all our boxes so far. So for a quick test setup I did not gave it much thought and just used it. However, we noticed massive loss in interactivity during heavy I/O, to and extend where editors, like vi, would even stall for seconds. Additionally, performance appeared sub-par during massive compilations with ccache looking up cache files in millions of files or just wiping (rm -rf) some million files of T2 Linux test-build sandboxes or simulation data areas.
As a quick internet search did not brought up recent filesystem benchmarks, I thought it might be a good idea to finally get the T2 magaZine section going with a filesystem benchmark article #1. And here we are.
The hardware
As the big 8-way Xeon server was under production I choose my dual-core 2GHz G5 (IBM 970) 64-bit PowerPC workstation with a second 160GB SATA disc for the test. I know it misses the RAID array and the endianss difference might waste some extra cycles doing byte swapping on some filesystems here and there, but all in all it should give an overal picture of the state-of-the-filesystems under Linux and and an impression about the stability and cleanlyness of the filesystem implementation (running on a not so standard 64bit, big-endian code-path) as well as an overall performance picture.
Inspired by a Linux Gazette article I choose some simple, but sort of real-world, operations as benchmark instead of synthetic ones like iozone. Those interested me most for our work-load, operating on deep and populated file hierarchies.
As little extra doozy I included the "work-in-progress" ext4 (as shipping with 2.6.24), the probably yet little known btrfs, and wanted to include the "still experimental and not yet in mainline" reiser4. However, reiser4 at least did not particularly liked the big-endian 64bit machine and oopsed quite a lot during the tests and thus did not yield particularly useful data - sorry.
For the records, the exact hardware configuration was: dual core PPC970MP (PowerMac11,2 - PowerMac G5 Dual Core) at 2GHz, Broadcom K2 SATA controller with a "ST3250820AS P" as test-drive, with Linux kernel 2.6.24 on T2 SDE 7.0-stable (2007/11/04) with gcc-4.2.2.
The results
First comes the file system creation. Not of particular interest for me, only included because others do, too:

Same applies for the first mount time:

Creating 100000 files with a single invocation of touch:

Run find on the directory with 100000 files. Mostly only included due the the Linux Gazetta article, particularly not that interesting as mostly in the sub-second domain:

Next comes removing (rm -rf) the directory with 100000 files. This is of more interest for me as wiping huge sets of either build (T2) or test data sometimes already made me get a fresh coffee:

Now we continue the same game with directories. First the creation:

Running find on them:

And last but not least removing them:

Now we put some more payload into a huge collection of files in a single directory - 48k of zeros (from /dev/zero of course). Actually I found this particular payload while searching the internet for people's experience with filesystems and this particular load from someone complaining about XFS unlink (remove) performance. Actually a load where filesystems also differ a little more:
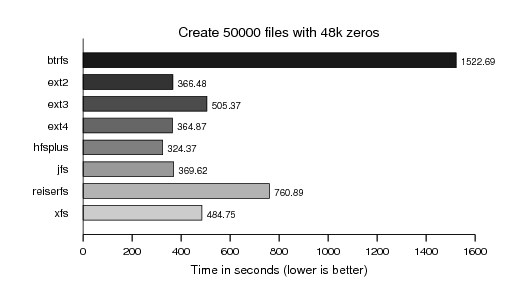
In particular XFS showing the known remove performance pattern:

After the basic functionality tests we put some more developer's i/o pattern to the filesystem. Starting with extracting the currently latest 2.6 (.24) Linux kernel. I did not imagine such a divergence of the filesystems in this test:

Re-readig the tree by creating a tar-ball (piped to /dev/null):

And again the cleanup (rm -rf). We already seen the XFS unlink performance above:

Finally, we apply a similar load using the T2 SDE source code, which consits of very many tiny (sub 4k) text description and patch files with the many additional .svn control (meta-data) files:

As I was particularly interested in the massiv i/o storm caused by svn operations (svn up, svn st) accessing and locking all the meta-data directories we measured a "svn st" run on the T2 tree. However, it did not differ as much as I estimated, probably because the data was still so hot, nicely sitting in caches:

Followed by creating yet again a tar-ball, however, this time writing it to the same disk, instead of /dev/null as with the previous kernel test:

And finally also removing the T2 source tree, sniff:

Epilogue
As I like to avoid religious flamewars I will not attempt to promote a particular filesystem in this article. Most noteably is the infamous XFS unlink performance. This raw data is for your further interpretation and for selection depending on your use case. This data is by no means complete. One could continue and benchmark different loads of different sizes like e.g. iozone performs, and also meassure the latency of parallel operations, those that annoyed me in real-life on the 8-way box with reiserfs (v3). Suggestions for a future match are welcome.
However, I like to point out that some file systems - though yielding quite good numbers durings this test - might not be that particular good choices for production machines, particularly I think the hfsplus (for Linux) implementation should be considered more a data-exchange solution for Macintosh systems, than a filesystem for 24x7 servers. Even if just because it does not get as much load and exposure as the other filesystems implemented and tested by a lot of people over the world.
But also the classic ext2/ext3 have their hickups. The limited maximal inodes are just one of then, as I even had to change the benchmark (for at least ext2/ext3)! In the first run my scripts created the 100000 directories of test #004 in just a single directory, for which ext2 and ext3 yielded some "too many links" (or so) error message when formated with the default settings and forced me to change the test to create the 100000 directories split into 4 top-level directories. Sigh!
Also btrfs-0.11 with the 2.6.24 kernel on powerpc64 oopsed a few times during the first file-system access. But as btrfs is officially declared as "on-disk format not finalized, definitely ready for production" and thus I kept the results to get a first reference. I also read in the btrfs repository that performance for many objects per directory was already improved.
For reiser4 the reiser4-for-2.6.24.patch from Edward Shishkin's reiser4 things page was applied. Too bad it did not worked out too well (read oopsed quite a lot) on the big-endian, 64-bit PowerPC64.
External links
The Author
René Rebe studied computer science and digital media science at the University of Applied Sciences of Berlin, Germany. He is the founder of the T2 Linux SDE, ExactImage, and contributer to various projects in the open source ecosystem for more than 20 years, now. He also founded the Berlin-based software company ExactCODE GmbH. A company dedicated to reliable software solutions that just work, every day.